Post
Architecture of Agents (lightly technical)
Follow up to the WHY Agents post, a lightly technical run-through on the how
June 10, 2026

A few weeks ago I wrote about why I built a two-agent system to run my consulting practice. This is not that post. This is the how: how the stack is wired, how I keep agents from doing damage, and what actually made them useful versus impressive-sounding demos that run once and get abandoned.
The Hardware
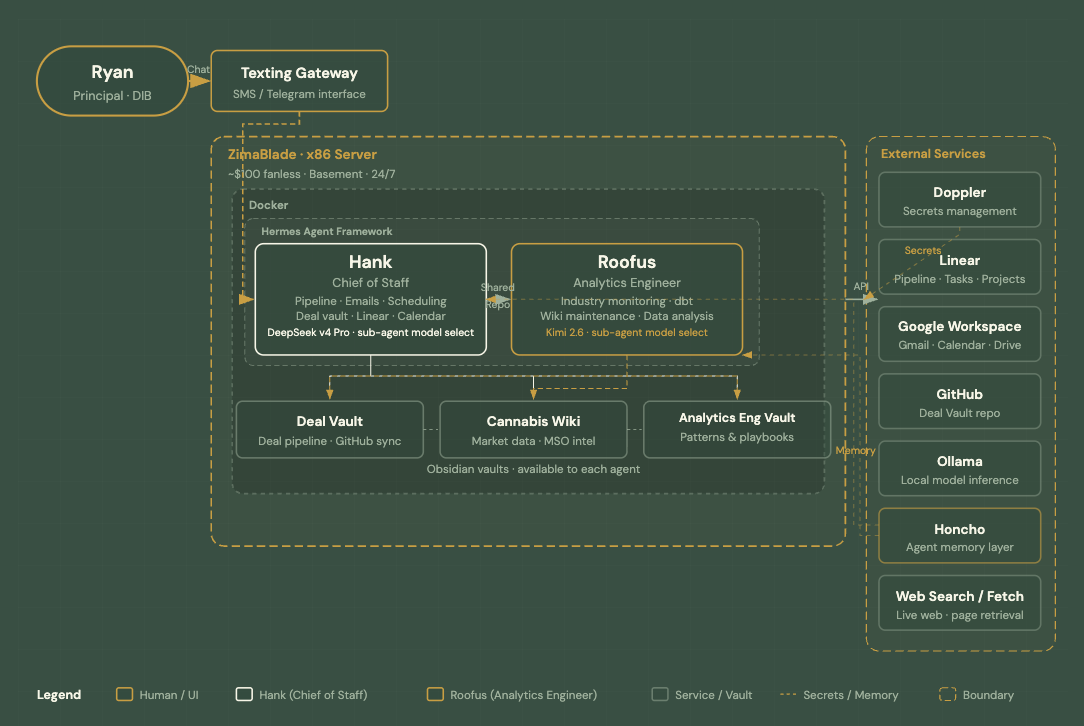
Everything runs on a ZimaBlade sitting on my desk. x86, fanless, about $100, always on. Docker via CasaOS. I SSH in with key-based auth when I need to get at it directly.
The compose files for both agents live in GitHub. That single decision has saved me more time than any other part of the setup. When a model updates, a config changes, or something breaks, I pull and restart. The entire agent environment is reproducible from a repo checkout.
What's Running
Both agents run on the Hermes Agent Framework inside Docker. Hermes gives each agent its own Soul.md, its own tool access profile, and its own internal scheduler. No host crontab, no system.md. Schedules are defined in the agent config and Hermes manages execution.
Hank is my chief of staff: pipeline tracking, morning briefings, meeting recaps, deal monitoring. Talks to Linear, Gmail, Calendar, and the deal vault. Fires on a schedule, pushes output over Telegram. Does not wait to be asked.
Roofus is my analytics engineer: dbt work, pipeline builds and monitoring, cannabis market research, wiki maintenance. Supports a cannabis intelligence product I'm building.
Both support sub-agent model selection — currently on DeepSeek and Kimi respectively, but the specific models matter less than the pattern. For certain tasks I hardcode the routing, because I already know which model fits the step better than a router would guess. A task that needs fast cheap extraction drops down for that step and returns. The primary model decides; it does not always do the work.
Inference
Inference runs on Ollama Cloud. No local GPU, no proxy layer in front of it. The ZimaBlade is the control plane, not the compute.
Hermes assembles the API call. On each run it pulls together three things: the session context for the task at hand, the agent's general context from its Soul.md, and persistent memory, then sends that to the model. The framework owns context assembly. The model owns judgment. Keeping those two responsibilities separate is most of what makes the system predictable.
The Soul.md
This is where the work lives. The framework handles the loop. The Soul.md defines the judgment.
Each Soul.md establishes identity, role, a priority stack, behavioral rules, domain knowledge, and explicit constraints on what the agent is not. That last part matters as much as the rest.
Hank's Soul.md defines a hard priority order: client relationships first, my time second, pipeline third. It has a named function called "shiny object defense." When scope starts expanding, Hank names the object, names what it's pulling away from, and gives a one-line cost. Flag once, clearly, don't lecture, move on. The cannabis industry context lives in the Soul.md too: MSOs, Metrc, 280E, rescheduling, key operators. He's not pulling that from the web on each run.
Roofus's Soul.md treats me as a technical peer. dbt layer conventions, naming standards, testing non-negotiables, and code quality rules are all defined explicitly. It also carries awareness of a preferred data model we're building and flags when a modeling decision has implications for it. One rule that has earned its place: if a task falls outside the data engineering domain, redirect to Hank. Hard boundary between the two agents.
A system prompt is not configuration. It is a model of how you actually work, and it's only as good as your honesty about that.
Memory
The hardest part of the build. Still iterating.
For the vault layer I follow the Karpathy wiki pattern. Instead of a vector database and a chunking pipeline, the agents author and maintain structured markdown files directly. Each vault has a raw/ folder for source material and a wiki/ folder where agents compile it into entity pages with bidirectional [[wikilinks]] and backlinks. The agents don't just query the vaults, they maintain them. Roofus ingests a new earnings report, creates or updates the relevant entity pages, and cross-links to operators, markets, and patterns already in the wiki. The graph compounds over time in ways you didn't explicitly design.
Both agents share three vaults in a shared GitHub repo: a deal vault, a cannabis wiki, and an analytics engineering vault. Either agent can read or write to any of them. Access is unrestricted by design; the separation between agents is convention, not permissions. I keep a clean vault separate from the working vault the agents write to. Agents promote distilled, validated content to the clean vault. Raw drafts and intermediate work stay in the messy one.
So how does an agent find the right page on a given run? Deliberate path reads, ripgrep, and curated map-of-content pages. No vector search.
The vaults follow a predictable schema: deals/<company>.md, moc/moc-*.md, regulatory/*.md. Path conventions are hardcoded into the skills that load them, so retrieval breaks into three patterns. \
Pre-baked context loading. The daily briefing skill loads a fixed set of pages every run: the sitemap index, the glossary, the federal rescheduling doc, and any operator pages cross-referenced from active deals. The cron definition tells it which pages to load, so it doesn't search for them.
Path-as-index retrieval. Ask Hank for the Acme deal status and he doesn't grep for "Acme." He knows the file is deals/acme-holdings.md. People and companies follow the same convention. The path is the index. When the path isn't known, search_files (ripgrep under the hood) handles content search or glob discovery. Not sexy. Deterministic and fast at roughly fifty files.
MOC as entry point. The map-of-content pages list every deal, its stage, the key insight, and wikilinks out to related pages. Land on a MOC, follow the wikilinks, pull the next layer. This is human-maintained graph traversal, not a generated index.
This works at current corpus size and stops working somewhere north of 500 pages. At that point path conventions are no longer fast enough and you need one of three things: a sitemap loaded on every run, which costs tokens; a real traversal strategy that follows wikilinks breadth-first until it has enough context; or an actual knowledge-graph layer with explicit entity-relationship edges. That last option is the GraphRAG convergence I'm already looking at. The wikilink graph is a knowledge graph. It just lacks edge types, entity resolution, and a query layer. Building those is the next step if the corpus keeps growing.
For persistent memory across sessions I currently use Honcho, but this is the part of the stack I'm most actively evaluating. The space is moving fast. Honcho, Hindsight, Mem0, Zep, and OpenBrain all approach the problem differently, with real differences in retrieval strategy, whether memory is user-scoped or session-scoped, and how much control you have over what gets written versus inferred. No clear winner yet.
The working principle: vaults hold durable reference knowledge, persistent memory holds live working context. Conflate the two and both degrade.
Risk Mitigation
Tool access is blast radius. Every capability you hand an agent is also the worst case if something goes wrong. I define per-agent tool profiles explicitly. Roofus does not have email access. Hank has write access to the vault repo but not to infrastructure — no compose files, no secrets, no agent config. The overlap is intentional and minimal.
Prompt injection is not theoretical. An agent that fetches web pages or reads documents can act on adversarial instructions embedded in that content. Tool restrictions reduce exposure. They do not eliminate it. At solo-operator scale the risk is manageable. At any real organizational scale you need runtime isolation, not just disciplined configuration.
Silent failure is the one that costs you. Several scheduled jobs depend on the output of another job. When an upstream job failed quietly early on, the downstream one produced garbage I might have acted on. Every job now has a verification step: did the dependency finish cleanly? If not, stop and surface it. An agent that fails loudly is a nuisance. One that fails silently is a liability.
Multi-agent collision is fixable with boring rules. Two agents writing to the same vault will conflict. Explicit handoff rules solve it: one agent produces, the other reviews, they do not write to the same file concurrently. Define this before the agents are running.
Secrets done right. Credentials in environment variables via Doppler. Nothing hardcoded, rotation on a schedule. The one part of this stack I'd hold up as enterprise-ready without qualification.
Making Them Actually Useful
A useful agent runs unattended, produces something you would have done yourself, and does not surprise you.
Remove yourself as a dependency. The agents do not wait for me. Hank's morning briefing fires at 8 AM regardless. The weekly deal review runs every Monday. Scheduling discipline is what separates a useful agent from a chatbot with extra steps.
Tight context produces better work than broad access. An agent with a narrow role and minimal tools consistently outperforms a generalist with a wide mandate. The hard boundary between Hank and Roofus, enforced in both Soul.md files, is what keeps each of them sharp.
Build the agent to model how you actually work, not how you wish you worked. Hank's shiny object defense exists because I needed it for myself first. If you build agents without accounting for your own working patterns, you get an agent that amplifies your bad habits instead of compensating for them.
Gaps
The control plane is Telegram. Convenient, not hardened. A proper authenticated interface is on the list.
Nothing watches the logs in real time. I catch problems on review, not in the moment. Acceptable at solo scale, not at team scale.
Subagent tool profiles are managed by hand. There is no runtime isolation layer underneath. First thing I'd close before recommending this architecture to a larger team.
The Diagram
Process clarity before tooling. Know how your work actually flows before you try to model it in an agent, and know which failures you can absorb. The technology is not the hard part.